
Costs. Benefits. Probabilities. For data analysts (or just human beings!) these concepts are key to our daily decision-making. Realize it or not, you’re constantly weighing up each one; from deciding which brand of detergent to buy, to the best plan of action for your business. For those working in data analytics and machine learning, we can formalize this thinking process into an algorithm known as a ‘decision tree.’
But what exactly is a decision tree? This post provides a short introduction to the concept of decision trees, how they work, and how you can use them to sort complex data in a logical, visual way. Whether you’re a newly-qualified data analyst or just curious about the field, by the end of this post you should be well-placed to explore the concept in more depth.
We’ll cover the following:
In its simplest form, a decision tree is a type of flowchart that shows a clear pathway to a decision. In terms of data analytics, it is a type of algorithm that includes conditional ‘control’ statements to classify data. A decision tree starts at a single point (or ‘node’) which then branches (or ‘splits’) in two or more directions. Each branch offers different possible outcomes, incorporating a variety of decisions and chance events until a final outcome is achieved. When shown visually, their appearance is tree-like…hence the name!
Decision trees are extremely useful for data analytics and machine learning because they break down complex data into more manageable parts. They’re often used in these fields for prediction analysis, data classification, and regression. Don’t worry if this all sounds a bit abstract—we’ll provide some examples below to help clear things up. First though, let’s look at the different aspects that make up a decision tree.
Decision trees can deal with complex data, which is part of what makes them useful. However, this doesn’t mean that they are difficult to understand. At their core, all decision trees ultimately consist of just three key parts, or ‘nodes’:
Connecting these different nodes are what we call ‘branches’. Nodes and branches can be used over and over again in any number of combinations to create trees of various complexity. Let’s see how these parts look before we add any data.
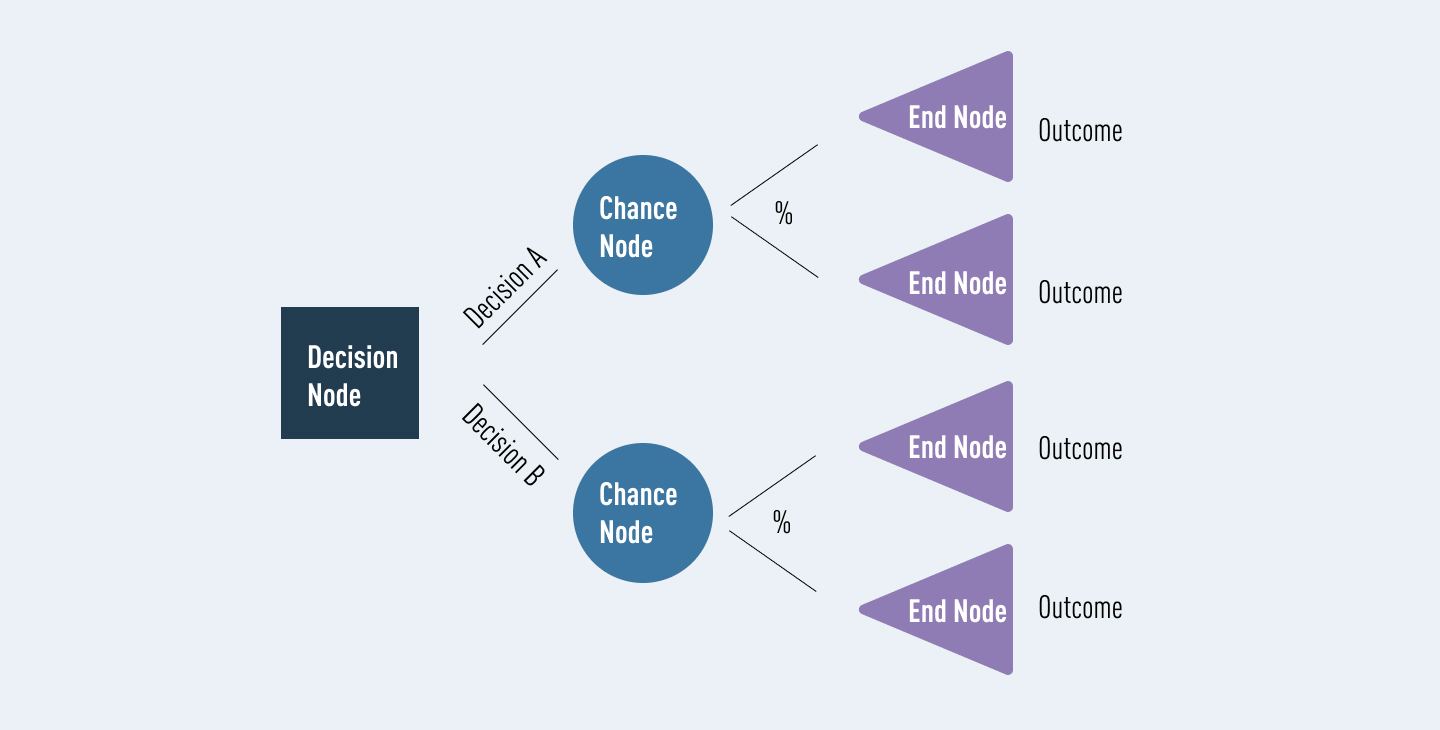
Luckily, a lot of decision tree terminology follows the tree analogy, which makes it much easier to remember! Some other terms you might come across will include:
In the diagram above, the blue decision node is what we call a ‘root node.’ This is always the first node in the path. It is the node from which all other decision, chance, and end nodes eventually branch.
In the diagram above, the lilac end nodes are what we call ‘leaf nodes.’ These show the end of a decision path (or outcome). You can always identify a leaf node because it doesn’t split, or branch any further. Just like a real leaf!
Between the root node and the leaf nodes, we can have any number of internal nodes. These can include decisions and chance nodes (for simplicity, this diagram only uses chance nodes). It’s easy to identify an internal node—each one has branches of its own while also connecting to a previous node.
Branching or ‘splitting’ is what we call it when any node divides into two or more sub-nodes. These sub-nodes can be another internal node, or they can lead to an outcome (a leaf/ end node.)
Sometimes decision trees can grow quite complex. In these cases, they can end up giving too much weight to irrelevant data. To avoid this problem, we can remove certain nodes using a process known as ‘pruning’. Pruning is exactly what it sounds like—if the tree grows branches we don’t need, we simply cut them off. Easy!
Now that we’ve covered the basics, let’s see how a decision tree might look. We’ll keep it really simple. Let’s say that we’re trying to classify what options are available to us if we are hungry. We might show this as follows:
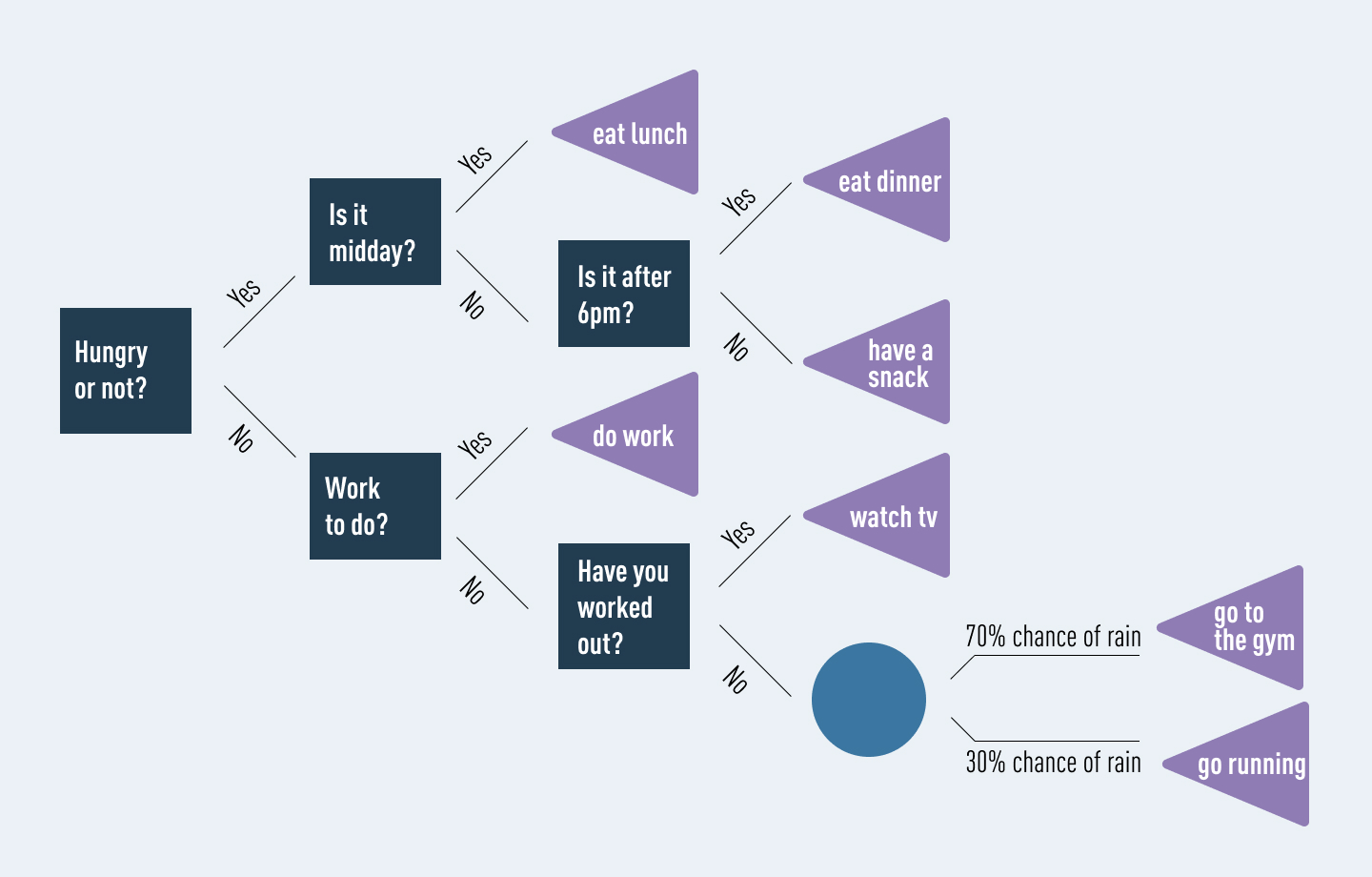
In this diagram, our different options are laid out in a clear, visual way. Decision nodes are navy blue, chance nodes are light blue, and end nodes are purple. It is easy for anybody to understand and to see the possible outcomes.
However, let’s not forget: our aim was to classify what to do in the event of being hungry. By including options for what to do in the event of not being hungry, we’ve overcomplicated our decision tree. Cluttering a tree in this way is a common problem, especially when dealing with large amounts of data. It often results in the algorithm extracting meaning from irrelevant information. This is known as overfitting. One option to fix overfitting is simply to prune the tree:
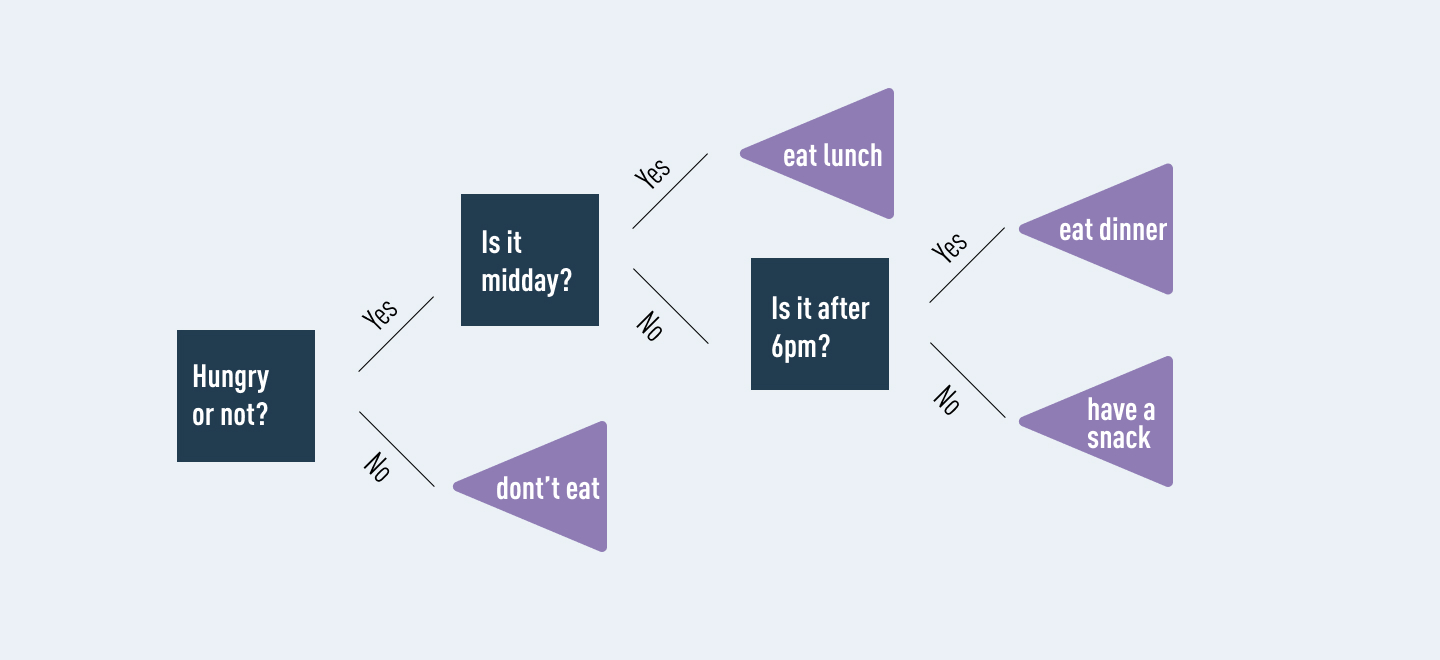
As you can see, the focus of our decision tree is now much clearer. By removing the irrelevant information (i.e. what to do if we’re not hungry) our outcomes are focused on the goal we’re aiming for. This is one example of a pitfall that decision trees can fall into, and how to get around it. However, there are several pros and cons for decision trees. Let’s touch on these next.
Used effectively, decision trees are very powerful tools. Nevertheless, like any algorithm, they’re not suited to every situation. Here are some key advantages and disadvantages of decision trees.
Despite their drawbacks, decision trees are still a powerful and popular tool. They’re commonly used by data analysts to carry out predictive analysis (e.g. to develop operations strategies in businesses). They’re also a popular tool for machine learning and artificial intelligence, where they’re used as training algorithms for supervised learning (i.e. categorizing data based on different tests, such as ‘yes’ or ‘no’ classifiers.)
Broadly, decision trees are used in a wide range of industries, to solve many types of problems. Because of their flexibility, they’re used in sectors from technology and health to financial planning. Examples include:
As you can see, there many uses for decision trees!
Decision trees are straightforward to understand, yet excellent for complex datasets. This makes them a highly versatile tool. Let’s summarize:
Now you’ve learned the basics, you’re ready to explore this versatile algorithm in more depth. We’ll cover some useful applications of decision trees in more detail in future posts.
New to data analytics? Get a hands-on introduction to the field with this free data analytics short course, and check out some more tools of the trade:
This article is part of:
Writer for The CareerFoundry Blog
Will is a freelance copywriter and project manager with over 15 years' experience helping firms communicate all things tech- and education-related. His words have been published in print and online, including in the Daily Telegraph, TES, and across other education sector media. He's also known for his ability to complete a Rubik's Cube in under five seconds, but it has to be seen to be believed.

 Courses in Germany & How You Could Take Them for Free" width="" height="" />
Courses in Germany & How You Could Take Them for Free" width="" height="" />

CareerFoundry is an online school for people looking to switch to a rewarding career in tech. Select a program, get paired with an expert mentor and tutor, and become a job-ready designer, developer, or analyst from scratch, or your money back.